AnimateDiff: Animate Your Personalized Text-to-Image Diffusion Models without Specific Tuning (ICLR'24 spotlight)
Click to Play the Animations!
Generated with CivitAI models: ToonYou Lyriel majicMIX Realistic RCNZ Cartoon 3d
Click to Play the Animations!
Generated with CivitAI models: ToonYou Lyriel majicMIX Realistic RCNZ Cartoon 3d
Methodology
With the advance of text-to-image models (e.g., Stable Diffusion) and corresponding personalization techniques (e.g., LoRA and DreamBooth), it is possible for everyone to manifest their imagination into high-quality images with an affordable cost.
Subsequently, there is a great demand for image animation techniques to further combine generated stationary images with motion dynamics.
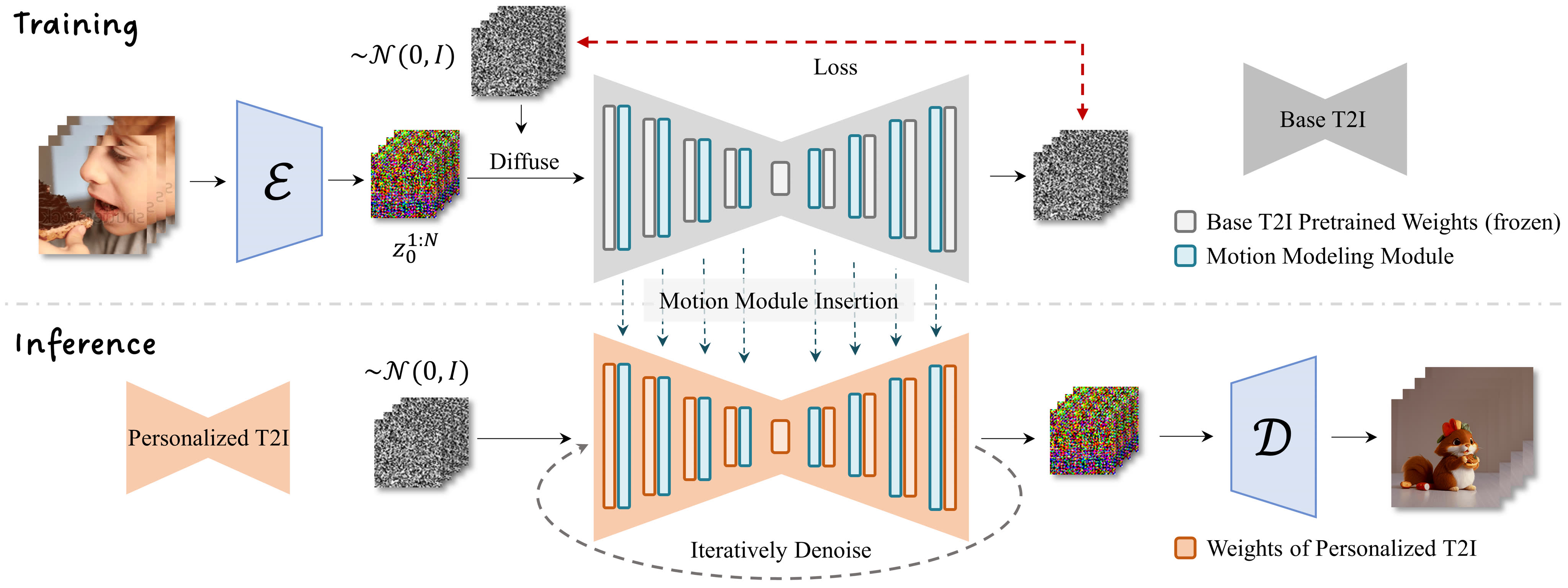
In this project, we propose an effective framework to animate most of existing personalized text-to-image models once for all, saving the efforts in model-specific tuning.
At the core of the proposed framework is to append a newly-initialized motion modeling module to the frozen based text-to-image model, and train it on video clips thereafter to distill a reasonable motion prior. Once trained, by simply injecting this motion modeling module, all personalized versions derived from the same base one readily become text-driven models that produce diverse and personalized animated images.
Gallery
Here we demonstrate best-quality animations generated by models injected with the motion modeling module in
our framework.
Click to play the following animations.
Model: ToonYou
Model: Counterfeit V3.0
Model: Realistic Vision V2.0
Model: majicMIX Realistic
Model: RCNZ Cartoon
Model: RCNZ Cartoon
Model: TUSUN
Model: FilmVelvia
Model: GHIBLI Background
Model: InkStyle
Supplement
Here we show results using the same prompt with the same model, demonstrating that our method dose not break the diversity of the original model. Click to play the following animations.
Model: ToonYou
Model: Lyriel
BibTeX
@misc{guo2023animatediff,
title={AnimateDiff: Animate Your Personalized Text-to-Image Diffusion Models without Specific Tuning},
author={Yuwei Guo and Ceyuan Yang and Anyi Rao and Zhengyang Liang and Yaohui Wang and Yu Qiao and Maneesh Agrawala and Dahua Lin and Bo Dai},
booktitle={arXiv preprint arxiv:2307.04725},
year={2023},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
Project page template is borrowed from DreamBooth.